![]()
Itead Studio Sonoff SC Revisited
A few months ago I wrote about the Sonoff SC sensor hub by Itead Studio. It's a device with a Sharp GP2Y1010AU0F [Aliexpress] dust sensor, a DHT11 humidity and temperature sensor, an LDR as light sensor and a mic. The sensors are driven by an ATMega328P microcontroller but there is also an ESP8266 on board for WiFi communication, a pretty standard set up when you have several sensors and the ESP8266 GPIOs are just not enough....
![]()
RFM69 WIFI Gateway
Some 3 years ago I started building my own wireless sensor network at home. The technology I used at the moment has proven to be the right choice, mostly because it is flexible and modular.
MQTT is the keystone of the network. The publisher-subscriber pattern gives the flexibility to work on small, replaceable, simple components that can be attached or detached from the network at any moment. Over this time is has gone through some changes, like switching from a series of python daemons to Node-RED to manage persistence, notifications and reporting to several “cloud” services....
![]()
Rentalito goes Spark Core
The Rentalito is a never ending project. It began as a funny project at work using an Arduino UNO and an Ethernet Shield, then it got rid of some cables by using a Roving Networks RN-XV WIFI module, after that it supported MQTT by implementing Nick O’Leary’s PubSubClient library and now it leaves the well known Arduino hardware to embrace the powerful Spark Core board.
Spark Core powered Rentalito - prototype Spark Core The Spark Core is a development board based on the STM32F103CB, an ARM 32-bit Cortex M3 microcontroller by ST Microelectronics, that integrates Texas Instruments CC3000 WIFI module....
![]()
MQTT topic naming convention
Naming stuff is one of the core decisions one has to take while designing an architecture. It might not look as important as utilising the right pattern in the right place or defining your database model but my experience says that a good naming convention helps identifying design flaws.
In a previous post I introduced the network I'm building for my home monitoring system. As I said it will be based on MQTT, a lightweight messaging protocol....
![]()
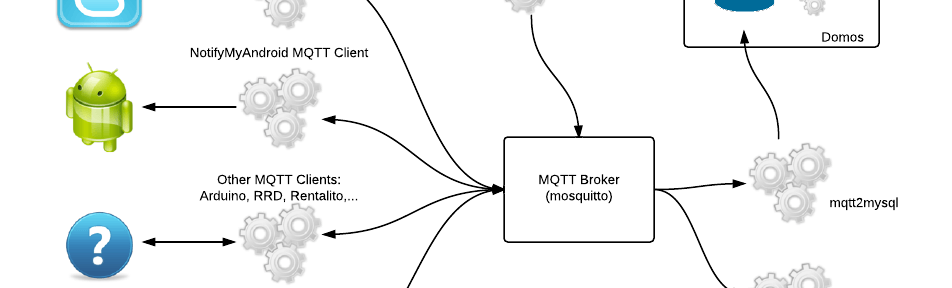
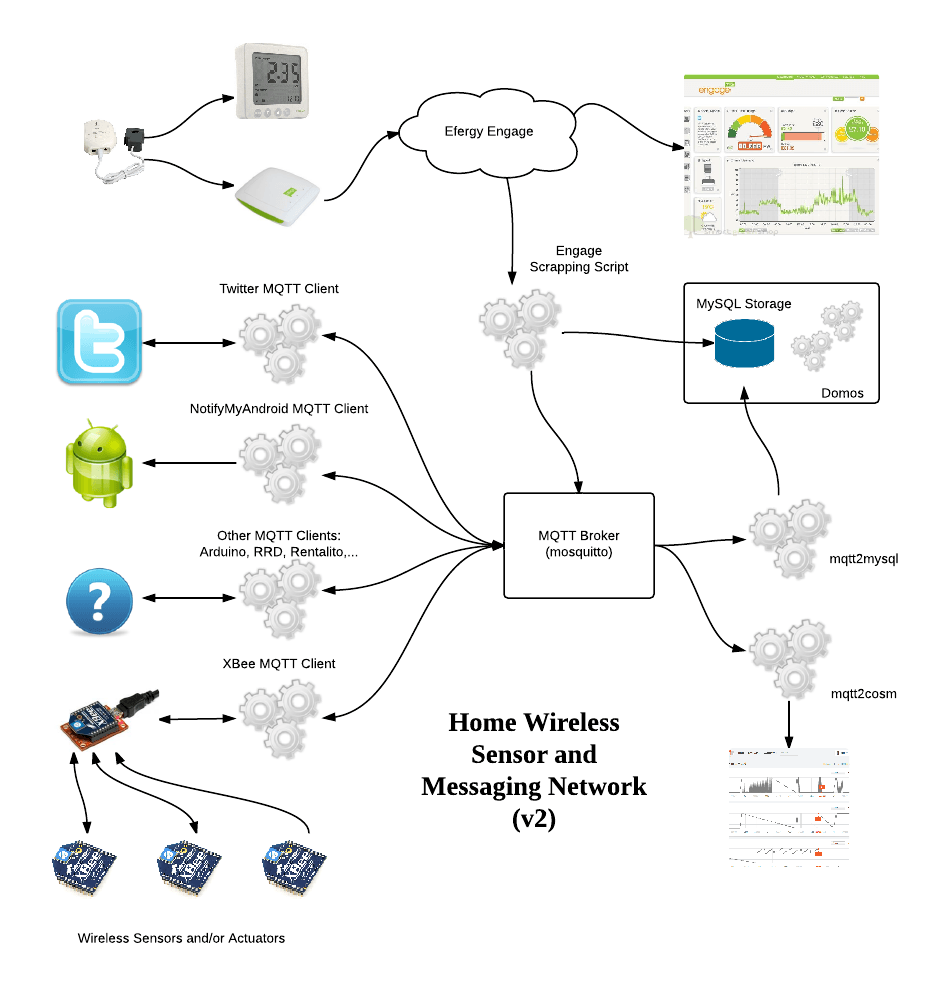
Home monitoring system
All of us tinkermen eventually end up working on a home monitoring/automation system sooner or later. And that's for me the big background project at the moment.
I have already some of the pieces in several stages of readiness but I was lacking an overall view of the system as a whole. My initial approach was to store everything in a MySQL database and develop a web application to graph the time series values....